Exercise Genomics
This is an excerpt from Advanced Exercise Physiology by Jonathan K Ehrman,Dennis J Kerrigan,Steven J Keteyian.
Contribution by Mark A. Sarzynski, PhD, University of South Carolina
The rapidly expanding field of exercise genomics advances our understanding of the preventive and therapeutic properties of exercise by increasing our knowledge about the physiology of exercise and human behavior. Although understanding the effects of various factors (e.g., environmental) on exercise-related phenotypes has long been of interest, understanding of the role of genetic factors (i.e., exercise genomics) is still in its infancy. Most of the major developments have occurred over the past 50 years. This section of the chapter does not have the capacity to fully review the field of genetics; therefore, the following sections introduce the basic concepts of genetics, deoxyribonucleic acid (DNA), and molecular biology relative to exercise physiology. A more thorough review on the topic can be found in Genetics Primer for Exercise Science and Health by Stephen M. Roth (2007).
Basics of Human Genetics
Genetics is the study of genes, heredity, and genetic variation in living organisms. The human genome, which contains all of the genetic material in human cells, consists of about 3 billion DNA base pairs. DNA encodes the instructions for the development, function, and reproduction of the entire human being. DNA is located in both the nucleus of the cell and the mitochondria, the majority of which is located in the nucleus. The nuclear genome comprises 22 pairs of autosomes (non-sex-specific chromosomes) and one pair of sex chromosomes for a total of 46 chromosomes. Humans inherit half of their genome from their mother (22 autosomes and an X chromosome) and half from their father (22 autosomes and either an X or Y chromosome). Women carry two copies of the X chromosome, whereas men carry one X chromosome and one Y chromosome. The presence or absence of the Y chromosome (responsible for testis development) determines the sex of the offspring.
Each DNA molecule consists of two complementary strands that each comprise four nucleotide bases - adenine (A), cytosine (C), guanine (G), and thymine (T) - that form a double helix. The binding between the two DNA strands is complementary: A always binds to T and C with G, creating complementary base pairs. The order of these nucleotide bases determines the meaning of the biological information encoded in that part of the DNA molecule. Specific sequences or regions of DNA that provide instructions to build ribonucleic acid (RNA) and proteins are called genes. Genes are the basic physical and functional units of heredity. The human genome contains about 20,500 genes. DNA found in the mitochondria is a circular double helix and contains 37 genes. The typical structure of a gene consists of many regions, including the coding region (exons), noncoding region (introns), promoter region (5'-end; upstream region; beginning of gene), and 3'-untranslated and terminator regions (3'-end; downstream region; end of gene; figure 11.2). The promoter region contains elements that direct the transcription of a gene (i.e., turn the gene on or off), whereas the terminator region contains the DNA sequence responsible for stopping the transcription of a gene.

The basic structure of a gene, including the upstream promoter region, the coding exons separated by introns, and the downstream terminator region at the end of the gene.
A central tenet of molecular biology describes the flow of information from DNA to RNA to proteins (figure 11.3). During the process of transcription, or gene expression, the nuclear DNA sequence found in a gene is read and copied onto a complementary strand of RNA called premature messenger RNA (mRNA) by the enzyme RNA polymerase. RNA is single stranded and contains the nucleotides A, G, C, and uracil (U), which replaces T and similarly binds only to A. Before the premature mRNA can be used to build protein, the noncoding regions of introns are removed, resulting in mature mRNA that consists of the coding exonic regions only. The mature mRNA then travels out of the nucleus and into the cell's cytoplasm, where it undergoes the process of translation. During translation, the genetic code is read by special organelles in the cell called ribosomes, which pair the mRNA to transfer RNA and eventually attach a corresponding amino acid to the polypeptide chain. Repetition of this step assembles a protein one amino acid at a time (figure 11.4). With just the four nucleotides used in three-letter combinations, the 20 standard amino acids are assembled.

The central principle of molecular biology, whereby DNA codes for RNA, which codes for proteins.
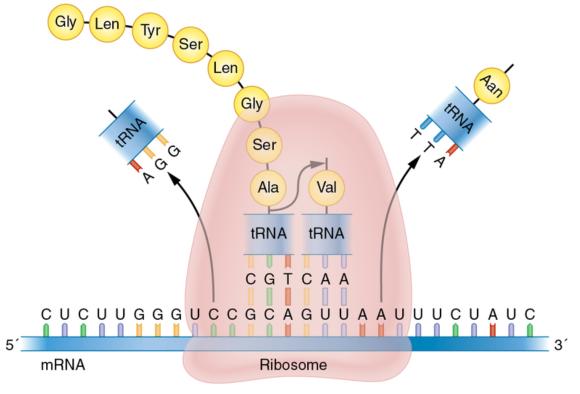
Overview of the translation of mRNA into protein. The ribosome binds to mRNA and moves one codon at a time downstream, where transfer RNA drops off an amino acid that links with the previous amino acid, thereby forming a polypeptide chain that continues until the ribosome reaches a stop codon.
Heritability and Genetic Variation
More than 99.9% of the DNA sequence in humans is similar. The 0.1% that differs is what makes each individual unique. Because family members share an even greater proportion of DNA sequence compared with unrelated individuals, analysis of familial aggregation (i.e., resemblance across family members) often is used to determine whether genetic variation contributes to a trait. For a given trait, familial aggregation is tested by comparing the variance between families with the variance within family members. For example, the HERITAGE Family Study examined the familial resemblance for maximal oxygen uptake (![]() O2max), the gold standard measure of cardiorespiratory fitness, in 426 sedentary subjects from 86 nuclear families. The authors found that achieved levels of
O2max), the gold standard measure of cardiorespiratory fitness, in 426 sedentary subjects from 86 nuclear families. The authors found that achieved levels of ![]() O2max clearly aggregate in families; there was 2.7 times more variance between different families than within families for adjusted
O2max clearly aggregate in families; there was 2.7 times more variance between different families than within families for adjusted ![]() O2max. Figure 11.5shows that some families tended to have below-average
O2max. Figure 11.5shows that some families tended to have below-average ![]() O2max values, whereas others had above-average values. Because families share genetic factors as well as similar environmental factors (e.g., diet, education, physical activity, and sedentary behaviors), further analyses are needed to determine whether the familial resemblance in
O2max values, whereas others had above-average values. Because families share genetic factors as well as similar environmental factors (e.g., diet, education, physical activity, and sedentary behaviors), further analyses are needed to determine whether the familial resemblance in ![]() O2max is due to genetic or environmental factors.
O2max is due to genetic or environmental factors.
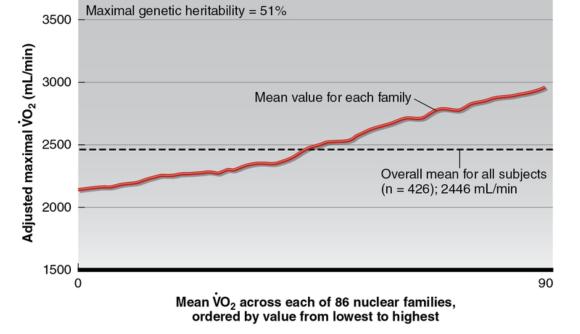
General depiction of familial aggregation for adjusted
Heritability is an estimate of how much of the variation in a trait is due to genetic factors alone. Heritability estimates are quantified by comparing trait similarities between pairs of relatives with different degrees of relatedness. Thus, twin, adoption, and family studies commonly are used to distinguish between the contribution of genetic and environmental factors on the familial aggregation of a trait. For example, a pattern of significant correlations among siblings and between parents and siblings but not between spouses would imply that the familial resemblance primarily is due to genetic factors, whereas significant correlations between spouses and lesser correlations between siblings or between parents and siblings would suggest a stronger influence of shared environmental factors such as diet and exercise habits. In the HERITAGE Family Study, the authors estimated that the genetic heritability of ![]() O2max was 51%. In addition to
O2max was 51%. In addition to ![]() O2max, numerous exercise-related traits have been shown to have a significant genetic component, as evidenced by their estimated heritability levels from twin and family studies (table 11.5).
O2max, numerous exercise-related traits have been shown to have a significant genetic component, as evidenced by their estimated heritability levels from twin and family studies (table 11.5).
After familial aggregation and heritability have been estimated for a trait, the next step is to determine which specific genetic factors contribute to the trait. Here, the term genetic factors refers to genetic variation or differences in the DNA sequence that may influence the information contained in a gene, thus resulting in trait variability between individuals. A variant nucleotide found at a mutation or polymorphism is known as an allele. Typically, two alleles are found at a polymorphism in the genome (e.g., A and G). Because genes come in pairs (one inherited from the mother and the other from the father), every individual has a pair of alleles for each mutation or polymorphism. The combination of alleles at any mutation or polymorphism is known as a genotype (i.e., that part of the genetic makeup that determines specific characteristics or phenotype). Thus, an individual may have either two copies of the same allele or one copy each of the variant allele. For example, if the nucleotides A and G are found at a particular polymorphism, an individual could have one of the following three genotypes: A/A, A/G, or G/G. An individual is a homozygote if they carry two copies of the same allele (e.g., A/A or G/G), whereas a heterozygote carries one of each allele (e.g., A/G). There are several forms of genetic variation, the most common of which is the single nucleotide polymorphism (SNP). An SNP is a single position in the DNA sequence where more than one nucleotide base is found in greater than 1% of the population. There are more than 10 million SNPs in the human genome. A mutation differs from a polymorphism in that the rare allele is found in less than 1% of the population.
Future Directions and Outlook
The field of exercise genomics has rapidly expanded over the past two decades with the advent of next-generation sequencing technologies, allowing for higher throughput and less expensive sequencing of common and rare variants. However, the field is mired by a general reliance on the candidate gene approach and observational studies with small sample sizes. Furthermore, lack of suitable replication studies or available DNA samples has made the replication of findings a difficult task, particularly for genome-wide studies. Thus, moving forward, exercise genomics needs to utilize a systems biology approach that integrates data from multiple technologies, including genomics, transcriptomics, metabolomics, proteomics, and epigenomics, among others. This will require large, well-designed, well-powered collaborative studies with replication from multiple sources along with the development of computational and bioinformatics tools and expertise within the field. Ultimately, identifying the genetic factors underlying the variability in health- and fitness-related traits due to regular exercise would significantly contribute to the study of the biology of adaptation to exercise and the development of an exercise component of personalized preventive and therapeutic medicine.
Learn more about Advanced Exercise Physiology.
More Excerpts From Advanced Exercise PhysiologySHOP

Get the latest insights with regular newsletters, plus periodic product information and special insider offers.
JOIN NOW